Advanced Reinforcement Learning
Highlighted below are some of the key results of FractalBrain in the Reinforcement Learning setting. Particular emphasis is put on the data efficiency of the algorithm, its across-domain generality and adaptability towards model drift and resiliency to physical damage to the learned model.
Similarly to a Human Brain, data efficiency of FractalBrain is considered as not only the number of training examples that the algorithm requires in order to master a given domain, but crucially, the complexity of the examples themselves. That is, the phenomenal data efficiency of the human brain, manifests itself by the brain ability to master a domain even when only a tiny fraction of information from the domain examples is processed by the brain. For example, when recognizing hand-written digits, the eye provides the brain with only a fraction of the high-resolution pixel information from the underlying digits.
As shown below, FractalBrain image recognition operates using the same principles, requiring only 4% of the visual information to solve the underlying hand-written digit recognition task. To this end, FractalBrain employs active sensing, that is, it uses RL to discover the optimal saccadic strategies (eye glances) that collect only the minimum necessary information for the task at hand. Remarkably, the optimal saccadic strategies found contain on average only 2.3 saccades, as visualised below.
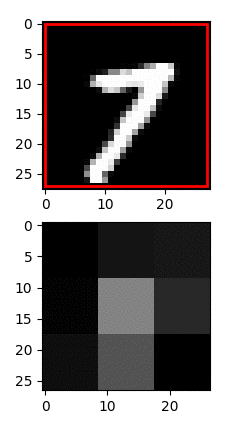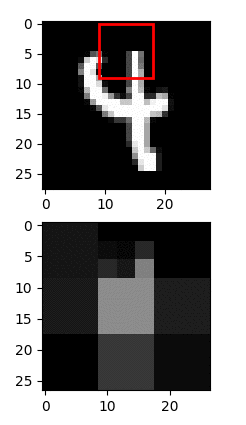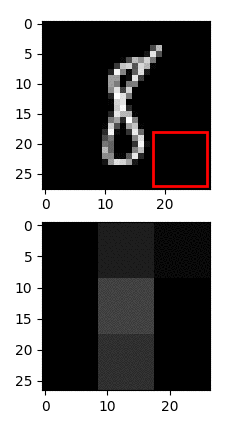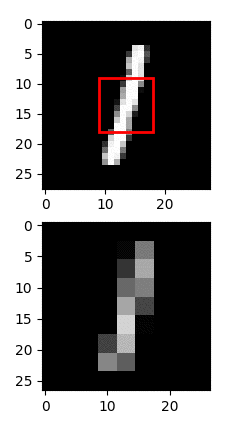
FractalBrain image recognition using active sensing
Uses 4% of Visual Information on MNIST classification
Trained agent needs ~2.3 saccades / digit = 4% information
The importance of the active sensing mechanism that the Human/Fractal Brain comes equipped with is even more pronounced in real-world domains that are inherently partially observable, that is, when the domain information in its entirety is simply not available to the agent. Examples of such domains range from sensor networks employing active radars to indoor/outdoor humanoid robot navigation. Consider for example a 3D navigation problem (Single room and T-maze below), where the agent only has a partial view of the domain (at its current location) and needs to find a green box. Solving this task requires the FractalBrain to fuse its 3D navigation strategy (to traverse the maze) and active sensing strategy (to locate the green box within its FOV) - a task that the agent learns to master, as seen below.
Also shown is a real-time visualisation of FractalBrain inside activity when operating on the 3D navigation tasks at hand. Visible is a regional arrangement of FractalBrain compute units (corresponding to cortical micro-columns), each consisting neurons grouped into L1, L2/3, L4, L6 and L6 cortical levels.
FractalBrain: Outside Activity


FractalBrain: Inside Activity


One of the key advantages of FractalBrain is that it provides a general-purpose RL algorithm, rather than a specific-purpose solution (e.g. SLAM for 3D navigation). To illustrate this point, highlighted below are the results of using FractalBrain (equipped with active sensing) on a suite of diverse, mini Atari-2600 video games. Across all the domains tested (Enduro / Pong / Gathering / Qbert / RiverRaid / SeekAvoid) visible is a strong learning curve of FractalBrain, with the agent performance converging asymptotically on the 100% mark. While not shown here, the FractalBrain RL performs equally well of the suite of classical RL domains from the OpenAI Gym and DeepMind bSuite repositories.
Enduro
Pong
Gathering
Qbert
River Raid
Seek Avoid
Finally, what makes FractalBrain RL unique is the system adaptability to model drift and resiliency to physical damage to the learned model. This is accomplished thanks to the continual expansion and distillation of the underlying FractalBrain connectome, as outlined here.
Production ready
Production ready
Production ready
Production ready
Production ready
Production ready
We are currently testing FractalBrain RL in an advanced Starship Landing Simulator. Specifically, we are interested in FractalBrain adaptability to unforeseen air density fluctuations and unforeseen abnormalities in its propulsion and avionic sub-systems, to expand the overall Starship mission envelopes. Contact us if you are interested in learning more about this case study and its deployment.
landing difficulty = Easy
landing difficulty = Hard